3 Erste Schritte
3.1 Zahlen
Wir haben in der Einleitung bereits das Rechnen mit Zahlen in R kennengelernt. Zahlen gehören zu den grundlegendsten Arten von Daten, die wir in R verarbeiten können. Mit ihnen können wir eine Reihe von arithmetischen Berechnungen durchführen:
x + y– Addition vonxundyx - y– Subtraktion vonxundyx * y– Multiplikation vonxundyx / y– Division vonxdurchyx ^ yoder alternativx ** y– Potenzierung,xhochy
Bis jetzt haben wir nur mit ganzen Zahlen gerechnet. Wir können aber auch mit Zahlen rechnen, die Nachkommastellen haben. Zahlen mit Nachkommastellen haben eine Besonderheit in R: Wir verwenden nicht ein Komma, sondern einen Punkt als Dezimaltrennzeichen, wie im Englischen.
## [1] 25## [1] 4.75Zahlen werden aber auch manchmal in der sogenannten wissenschaftlichen Notation dargestellt – vor allem, wenn sie sehr groß oder sehr klein sind (z.B. p-Werte). Wenn wir beispielsweise die Zahl 0.0000000012 in R eingeben, erhalten wir 1.2e-09 als Ausgabe. Dies ist kein Fehler, sondern lediglich eine andere Darstellung dieser Zahl. Bei der wissenschaftlichen Notation hat eine Zahl zwei Teile, die von einem e voneinander getrennt werden: Der erste Teil ist ein Faktor, während der zweite Teil der Exponent einer Zehnerpotenz ist. Ausgeschrieben wäre diese Zahl aus der wissenschaftlichen Notation: \(1.2\cdot 10^{-9}\) und damit äquivalent zu 0.0000000012.
3.2 Variablen
Sicherlich wollen Sie Ihre Daten nicht nur in der Konsole ausgeben lassen und bearbeiten, sondern auch in Variablen speichern. Variablen sind Bezeichnungen, mit deren Hilfe Sie auf gespeicherte Daten zugreifen. Sobald eine Variable definiert wurde, können Sie immer wieder darauf zugreifen. Variablen werden mit Hilfe des <- Operators definiert.
Sie können sich die Werte dieser Variablen ausgeben lassen, indem Sie die Variablennamen in der Konsole eingeben und Enter drücken.
## [1] 2Jetzt können Sie bereits erste Berechnungen mit Variablen durchführen:
## [1] 5## [1] 6In R lassen sich sämtliche Objekte – nicht nur einzelne Zahlen, sondern auch Datentabellen, Wortlisten oder sogar Ergebnisse komplizierter Analysen – in Variablen speichern. Der Workflow ist so ausgelegt, dass Sie die Ergebnisse einer Analyse in einer Variable speichern und von dort aus weiterverarbeiten können, z.B. um APA-konforme Tabellen oder Grafiken zu erstellen oder sich Effektstärkemaße ausgeben zu lassen. Im weiteren Verlauf des Kurses lernen Sie andere Datentypen kennen, die in Variablen gespeichert werden können.
Variablennamen können auch Umlaute, Unterstriche (“_“) und Punkte (”.”) enthalten, sie dürfen aber nicht mit einer Zahl oder einem Unterstrich beginnen.
Achtung: Wenn Sie eine Berechnung mit einer Variable durchführen und das Ergebnis dieser Berechnung speichern möchten, müssen Sie es wieder eine Variable zuweisen – es wird nicht automatisch gespeichert!
Wenn Sie sich jetzt x und z ausgeben lassen, sehen Sie, dass sich nichts an x geändert hat – das Ergebnis der Berechnung wurde nicht in der Variable x abgespeichert. In der Variable z hingegen sehen Sie das Ergebnis Ihrer Berechnung.
## [1] 2## [1] 20x, y und z sind denkbar schlechte Variablennamen! Gute Variablennamen sprechen zu den R Benutzer:innen, d.h. dass der Name eine Variable verrät, was sich “in” dieser Variable verbirgt. Deswegen sollten Sie sich immer bemühen, möglichst klare und eindeutige Variablennamen zu vergeben.
# Beispiele für gute Variablennamen
durchschnittliches_Alter <- 23
MW_Alter <- 23
durchschnittliches_Evaluationsergebnis_KursA <- 2
MW_Evaluationsergebnis_KursA <- 2Scheuen Sie sich nicht vor langen Variablennamen! Je besser und klarer Sie Ihre Variablen definieren, desto einfacher wird es sowohl Ihnen als auch anderen fallen, Ihren Code nachzuvollziehen. Besonders einfach lesbar sind längere Variablennamen, wenn Sie unterschiedliche Elemente des Variablennamens mit einem Unterstrich trennen. Diese Konvention wird auch in diesem Kurs verwendet.
Achtung: Variablennamen beachten Groß- und Kleinschreibung! Wenn wir eine Variable den Namen durchschnittliches_Alter zuweisen, müssen wir auch diesen Namen – genau so, wie wir ihn geschrieben haben – verwenden, um wieder auf die Variable zuzugreifen. Würden wir stattdessen beispielsweise durchschnittliches_alter (kleingeschriebenes A, bei Alter) oder Durchschnittliches_Alter (großgeschribenes D am Anfang) schreiben, würden wir eine Fehlermeldung bekommen, dass die Variable nicht gefunden werden konnte.
3.3 Funktionen
Wir sind alle bereits mit Funktionen aus dem Mathematikunterricht vertraut. Trigonometrische, logarithmische und Wurzelfunktionen sind auf jedem Schultaschenrechner vorhanden und geben uns eine Berechnung basierend auf unserer Eingabe zurück.
Funktionen in R haben eine ganz ähnliche Aufgabe und die meisten Funktionen, die wir bereits aus dem Mathematikunterricht kennen, finden sich auch wieder in R. Funktionen stellen in erster Linie eine Reihe von Anweisungen dar, die ausgeführt werden. Beispielsweise besteht die Berechnung des Mittelwerts aus zwei Anweisungen: (1) wir müssen alle Zahlen zu einer Summe addieren und (2) diese Summe durch die Anzahl der Zahlen dividieren.
Anstatt beide Anweisungen immer wieder separat zu schreiben, ist es deutlich einfacher und übersichtlicher eine Funktion hierfür zu definieren, die diese Schritte ausführt. Daher sind Funktionen besonders für wiederkehrende Abläufe sinnvoll.
Funktionen erkennt man in der Regel daran, dass der Name der Funktion von Klammern () gefolgt wird. Oft stehen zwischen den Klammen auch noch Daten oder Variablen, die als Eingabe verwendet werden und an die Funktion übergeben werden, die sogenannenten Funktionsargumente.
In R sind bereits über tausend Funktionen eingebaut. Als statistische Programmiersprache, sind die meisten Funktionen darauf ausgelegt, mathematische und statistische Berechnungen durchzuführen.
3.3.1 Funktionsargumente
Funktionen haben sogenannte Funktionsargumente und damit eine Art Platzhalter, die wir einer Funktion als Eingabe übergeben können. Viele Funktionen haben nur ein einziges Funktionsargument, beispielsweise die Wurzelfunktion oder die Exponentialfunktion. Es gibt aber auch Funktionen, die mehr als ein Funktionsargument besitzen.
Nehmen wir als Beispiel die Funktion round() aus R. Sie rundet Zahlen auf eine gewisse Anzahl an Nachkommastellen, die wir selbst festlegen können. round() hat daher auch zwei Funktionsargumente: Das erste Argument entspricht den Zahlen, die gerundet werden sollen und das zweite Argument, der Anzahl der Nachkommastellen, auf die gerundet werden soll. Einzelne Funktionsargumente werden jeweils mit einem Komma , voneinander getrennt in der Klammer geschrieben.
Wenn wir also beispielsweise die Zahl 0.0249 auf drei Nachkommastellen runden wollten, könnten wir dies in R mit folgendem Aufruf tun:
## [1] 0.0253.3.1.1 Benannte Funktionsargumente
Funktionsargumente in R haben auch Namen. Sie funktionieren damit nicht nur wie einfache Platzhalter, sondern analog zu Variablen, die dann innerhalb der Funktion verwendet werden. Wir können die Namen der Funktionsargumente auch mit angeben, wenn wir eine Funktion aufrufen.
Um herauszufinden, wie die Funktionsargumente benannt sind, können wir entweder in RStudio mit dem Cursor auf eine Funktion gehen und F1 auf der Tastatur drücken oder die Dokumentation anschauen (z.B. indem wir ein Fragezeichen gefolgt von dem Funktionsnamen in die Konsole eingeben: ?round).
Wenn wir dies für round() tun, erhalten wir die Funktionsdefinition: round(x, digits = 0). Die Funktion round() hat damit zwei Argumente: x und digits, die wir auch entsprechend angeben könnten:
## [1] 0.025Wenn wir Funktionsargumente mit ihrem Namen angeben, können wir dies in jeder beliebigen Reihenfolge tun! Wenn wir allerdings Funktionsargumente ohne Bezeichnung angeben, muss dies in der Reihenfolge erfolgen, wie sie in der Dokumentation steht.
## [1] 0.0253.3.1.2 Standardparameter
Viele Funktionen in R haben Funktionsargumente mit Standardparametern. Das heißt, dass wir das Funktionsargument nicht zwangsläufig angeben müssen. Wenn wir ein Funktionsargument nicht angeben, das einen Standardparameter hat, wird dieser Standardparameter automatisch als Funktionsargument genommen. Schauen wir uns dazu nochmal ein Beispiel an.
round() hat beispielsweise einen Standardparameter für das zweiten Funktionsargument (digits), dass die Anzahl der Nachkommastellen angibt, auf die gerundet werden soll. Dies erkennen wir daran, das bei der Funktionsdefinition ein Gleichheitszeichen nach dem Argument steht, welches den Standardwert des Parameters angibt: round(x, digits = 0). Das Funktionsargument digits hat demnach einen Standardparameter von 0. Das heißt, dass round() jeweils auf eine ganze Zahl runden würde, wenn wir den zweiten Parameter nicht mit angeben.
## [1] 0.025## [1] 0Bei manchen Funktionsaufrufen wollen wir nur einige Funktionsargumente selbst angeben – für alle Übrigen sollen die Standardparameter verwendet werden. Hierfür können wir unser Wissen aus dem vorigen Abschnitt nutzen: Wir geben einfach nur jeweils die Funktionsargumente mit ihren Namen an, die wir selbst angeben wollen und lassen den Rest frei. Für die freigelassenen Funktionsargumente wird dann jeweils ihr Standardparameter verwendet.
3.4 Vektoren
Jede Spalte eines Datensatzes ist ein Vektor. In einem Vektor befinden sich mehrere Elemente eines Datentyps, also z.B. mehrere Zahlen oder mehrere Wörter. Vektoren werden mit Hilfe der “combine”-Funktion c erstellt.
# Hier wird ein numerischer Vektor mit den Elementen 1 bis 10 erstellt.
# Mit einem Doppelpunkt können alle ganzen Zahlen zwischen den beiden angegebenen Zahlen angesprochen werden.
Vektor_numeric <- c(1, 2, 3, 4, 5, 6:10)Mit jedem Datentyp können Sie unterschiedliche Operationen durchführen. Um sich den Datentyp eines Vektors anzeigen zu lassen, können Sie die Funktion mode verwenden.
## [1] "numeric"3.4.1 Datentyp numeric
Mit Vektoren vom Typ numeric (kurz num) können Sie verschiedene mathematische Operationen durchführen. Sie können diese Vektoren addieren, multiplizieren, usw. Wenn Sie eine Operation wie * 2 auf den Vektor anwenden, wird diese Operation auf alle Elemente des Vektors angewendet.
## [1] 2 4 6 8 10 12 14 16 18 20Wenn Sie hingegen zwei gleich lange Vektoren haben, wird jedes i-te Element des ersten Vektors mit dem i-ten Element des zweiten Vektors verrechnet. Das Element an Position 1 in einem Vektor wird dann mit dem Element an Position 1 im anderen Vektor gepaart, das Element an Position 2 in einem Vektor mit dem Element an Position 2 im anderen Vektor – und so weiter.
punkte_MC_Fragen <- c(5, 2, 2, 4, 3, 2, 1, 0, 1, 4)
punkte_offene_Fragen <- c(3, 4, 5, 0, 2, 3, 1, 3, 5, 1)
klausurergebnis <- punkte_MC_Fragen + punkte_offene_Fragen
klausurergebnis## [1] 8 6 7 4 5 5 2 3 6 53.4.2 Datentyp character
Wenn Sie in einer Variable Text abspeichern wollen, definieren Sie eine Variable vom Datentyp character (kurz chr). (Variablen vom Datentyp character werden auch oft Strings genannt.) Text wird mit doppelten oder einfachen Anführungszeichen angegeben:
## [1] "Alpha"## [1] "Beta"## [1] "character"Mit Vektoren des Typs character können Sie natürlich keine mathematischen Operationen durchführen. Sie sind aber nützlich, um bestimmte Daten zu kodieren, wie bspw. das Geschlecht oder das Studienfach von Versuchspersonen.
3.4.3 Datentyp logical
Der Datentyp logical (kurz logi) kodiert binäre Informationen – diese sind entweder TRUE oder FALSE.
## [1] TRUE## [1] FALSE## [1] "logical"Dabei werden TRUE und FALSE als logische Bedingungen interpretiert, die erfüllt oder nicht erfüllt sein können. Vektoren dieses Datentyps sind für die Datenaufbereitung unglaublich nützlich! Mit Hilfe eines Vektors vom Typ logical können Sie beispielsweise kodieren, welche Versuchspersonen die Studie vollständig abgeschlossen haben oder ob einzelne Beobachtungen Ausreißer darstellen. Sie werden diesen Datentyp häufig benötigen, wenn Sie in Datentabellen einzelne Fälle auswählen oder Versuchspersonen ausschließen möchten. Hierbei wird dann jeweils im Einzelfall überprüft, welche Fälle eine gewünschte Bedingung erfüllen (z.B. maximal 30 Minuten zur Bearbeitung eines Tests gebraucht haben) und daher in den weiteren Analysen eingeschlossen werden.
# Hier wird festgehalten, welche Versuchspersonen (id) die Studie
# vollständig abgeschlossen haben (Studie_abgeschlossen)
id <- 1:10
Studie_abgeschlossen <- c(TRUE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, TRUE, TRUE) Oft sollen mehrere Bedingung gleichzeitig überprüft werden, z.B. Personen, die jünger als 18 sind und maximal 30 Minuten zur Bearbeitung eines Tests gebraucht haben. Mehrere logische Bedingungen können durch logische Operationen miteinander verknüft werden.
Die gängigsten logischen Operationen sind UND (&), ODER (|) und NICHT (!). UND und ODER
verknüpfen jeweils zwei logische Bedingungen (sprich: zwei logische Werte, also TRUE/FALSE) miteinander und geben selbst einen logischen Wert zurück.
Die Verknüpfung UND ergibt dann TRUE, wenn beide Bedingungen erfüllt sind, d.h. nur wenn die erste und die zweite Bedingung jeweils auch TRUE sind.
## [1] TRUE## [1] FALSE## [1] FALSEDie Verknüpfung ODER ergibt dann TRUE, wenn mindestens eine der beiden Bedingungen erfüllt ist, d.h. wenn die erste oder die zweite Bedingung oder beide Bedingungen TRUE sind. Ganz wichtig: ODER gibt auch dann TRUE aus, wenn beide Bedingungen erfüllt sind!
## [1] TRUE## [1] TRUE## [1] FALSEDas logische NICHT invertiert eine logische Variable: Aus TRUE wird FALSE und umgekehrt. Das ist hier noch etwas abstrakt, wird aber später in den Kapiteln zur Datenaufbereitung noch klarer.
## [1] FALSE## [1] TRUEWie mathematischen Ausdrücke auch, haben logische Operationen ebenfalls eine Rangfolge, nach der sie ausgewertet werden. Daher kann es sinnvoll sein, Klammern () zu verwenden, um logische Operationen zu gruppieren.
## [1] TRUE## [1] FALSE3.4.4 Datentyp factor
Variablen vom Datentyp factor sind nützlich, um kategoriale Variablen zu kodieren. Dabei wird zunächst ein Vektor vom Typ numeric erstellt. Den einzelnen Werten dieses numerischen Vektors werden dann kategoriale Bezeichnungen zugewiesen.
Bedingung <- c (0, 1, 1, 0, 1, 0, 0, 1)
Vektor_factor <- factor(x = Bedingung,
levels = c(0, 1),
labels = c("Kontrollgruppe", "Experimentalgruppe"))
Vektor_factor## [1] Kontrollgruppe Experimentalgruppe Experimentalgruppe
## [4] Kontrollgruppe Experimentalgruppe Kontrollgruppe
## [7] Kontrollgruppe Experimentalgruppe
## Levels: Kontrollgruppe Experimentalgruppe## [1] "numeric"Dazu verwenden Sie die Funktion factor. Dieser Funktion übergeben Sie den numerischen Vektor Bedingung und definieren anschließend die Stufen des Faktors mit Hilfe des Argument levels (hier 0 und 1) sowie die Bezeichnungen mit Hilfe des Argument labels (hier Kontrollgruppe und Experimentalgruppe).
Es ist immer sinnvoll, Variablen als Faktoren zu definieren, wenn sie endliche Ausprägungen haben. Experimentelle Bedingungen, Messzeitpunkte oder das Geschlecht von Versuchspersonen sind typische Kandidaten, die als Vektoren vom Typ factor gespeichert werden. Der Vorteil dieses Variablentyps besteht darin, dass Sie dort die Zuordnung von numerischen zu verbalen Bezeichnungen direkt vornehmen können und nachher nicht mehr nachschlagen müssen, ob “0” oder “1” nun die Experimentalgruppe kodiert. Spätestens bei der Auswertung Ihrer Daten sollten Sie solche Variablen also immer als factor rekodieren.
Achtung: Sie können mit Faktoren keine mathematischen Operationen durchführen, auch wenn ihnen eigentlich numerische Kodierungen zugrunde liegen. In R werden Vektoren vom Variablentyp factor diesbezüglich ebenso wie Vektoren vom Variablentyp character behandelt.
3.4.5 Datentyp NA
Ein Vektor besteht in der Regel nicht nur aus Variablen vom Datentyp NA. In echten Datensätzen werden Sie aber immer mal wieder fehlende Daten haben. Diese werden in R als NA kodiert.
Achtung: In anderer Statistiksoftware wie z.B. SPSS hat sich die Konvention entwickelt, fehlende Werte nicht mit NA, sondern mit bestimmten nicht beobachtbaren numerischen Werten wie “-9” oder “-99” zu beschreiben. Wenn Sie mit einem solchen Datensatz arbeiten, der zuvor in einer anderen Statistiksoftware bearbeitet wurde, sollten Sie immer überprüfen, ob fehlende Werte anhand solcher numerischen Werte kodiert sind und diese als NA rekodieren.
3.5 Auswahl von Vektorelementen
Sie können auf einzelne Elemente eines Vektor zugreifen, indem Sie den Operator [] verwenden. In die eckigen Klammern wird die Position des Elements eingefügt, das Sie auswählen möchten. Dieses Vorgehen wird Indizierung genannt.
## [1] 9Sie können auch eine sogenannte Negativindizierung durchführen, d.h. im Index festhalten, welches Element Sie nicht auswählen möchten.
## [1] 3 7 0 1 1 4 5Selbstverständlich können Sie auch gleich mehrere Elemente auswählen. Wenn Sie z.B. alles vom zweiten bis fünften Element auswählen wollen, können Sie das im Index so vermerken: [2:5]. Ganz allgemein gilt: Die Zahl vor dem Doppelpunkt gibt an, wo die Indizierung beginnt, und die Zahl nach dem Doppelpunkt gibt an, wo die Indizierung endet.
## [1] 7 9 0 1Wenn Sie mehrere Elemente auswählen möchten, die nicht direkt nebeneinander stehen, müssen Sie diese mit dem “combine”-Operator c verknüpfen:
## [1] 7 4Die so ausgewählten Daten können Sie natürlich wieder in einer neuen Variable speichern:
3.6 Logische Vergleiche
Logische Vergleiche können genutzt werden, um bestimmte Fälle – z.B. einzelne Versuchspersonen – auszuwählen. Welche logischen Vergleiche für einen Datentyp sinnvoll sind, hängt von diesem Datentyp ab.
3.6.1 Datentyp numeric
Wenn Sie Daten vom Typ numeric haben, können Sie numerische Vergleiche durchführen. Sie können zum Beispiel überprüfen, welche Ihrer Versuchspersonen 18 Jahre oder älter sind. Dazu verwenden Sie den logischen Operator >=, den Sie als “größer oder gleich” interpretieren können (analog dazu liest sich <= als “kleiner oder gleich”.)
## [1] TRUE TRUE TRUE TRUE TRUE FALSE TRUE TRUEBei numerischen Vektoren können Sie folgende logischen Vergleiche durchführen: (a) gleich (==), (b) größer (>), (c) kleiner (<), (d) größer gleich (>=), (e) kleiner gleich (<=) oder (f) ungleich (!=). Wenn Sie einen logischen Vergleich mit einem gesamten Vektor durchführen, wird für jedes einzelne Element überprüft, ob es der logischen Bedingung entspricht (TRUE) oder nicht (FALSE).
## [1] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE3.6.2 Datentyp character
Vektoren vom Typ character lassen sich darauf überprüfen, ob diese identisch bzw. nicht identisch mit einer bestimmten Bedingung sind.
# Hier wird überprüft, welche Versuchspersonen Psychologie studieren...
Studienfach <- c("Psychologie", "Medizin", "Informatik", "Sportwissenschaft", "Biologie")
Studienfach == "Psychologie"## [1] TRUE FALSE FALSE FALSE FALSE## [1] FALSE TRUE TRUE TRUE TRUE3.6.3 Datentyp factor
Dieser logische Vergleich lässt sich auch mit Daten vom Typ factor durchführen.
Bedingung <- c (0, 1, 1, 0, 1, 0, 0, 1)
Bedingung <- factor(x = Bedingung,
levels = c(0, 1),
labels = c("Kontrollgruppe", "Experimentalgruppe"))
# Hier wird überprüft, welche Versuchspersonen der Experimentalgruppe angehören
Bedingung == "Experimentalgruppe"## [1] FALSE TRUE TRUE FALSE TRUE FALSE FALSE TRUE3.6.4 Rekodieren von Variablen mit Hilfe logischer Vergleich
Sie werden logische Vergleiche häufig anwenden, um Daten zu rekodieren. Schauen Sie sich dazu die folgenden Beispiele an.
Mit Hilfe logischer Vergleiche können Sie überprüfen, ob fehlende Werte nicht mit NA, sondern mit “-9” kodiert wurden, um diese anschließend zu rekodieren.
## [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUESie können das Ergebnis dieses logischen Vergleichs nun nutzen, um alle Werte, die als “-9” kodiert wurden, zu rekodieren. Dazu speichern Sie das Ergebnis des logischen Vergleichs einfach in einer neuen Variable ab.
Im nächsten Schritt benutzen Sie die neue erstellte Variable vom Typ logical, um alle Werte des Vektors Testwerte, die den Wert “-9” haben, durch NA zu ersetzen.
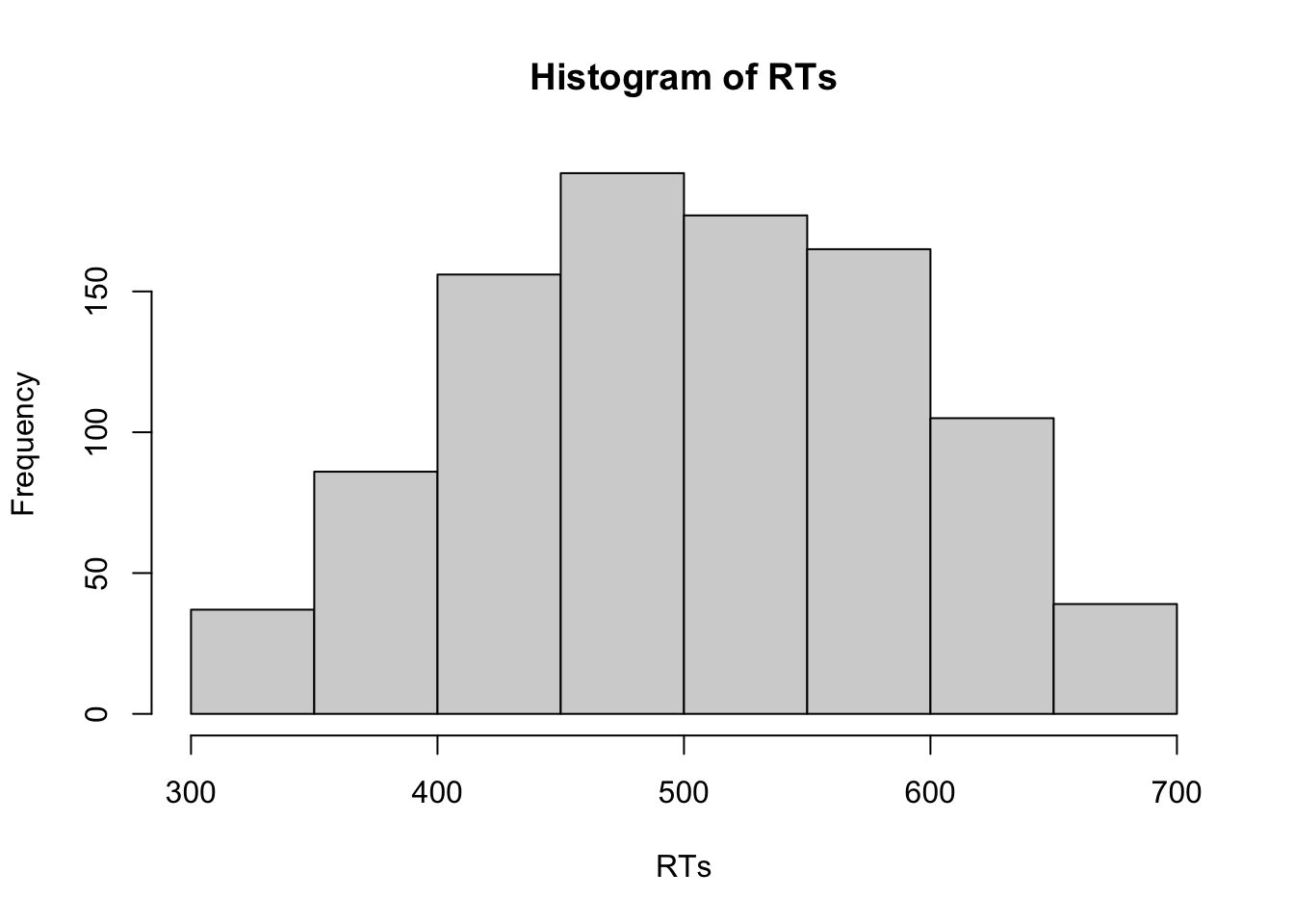
## [1] 80 57 93 85 72 65 NAGanz ähnlich können Sie bei einem Reaktionszeitexperiment alle Trials entfernen, in denen Versuchspersonen sehr langsam waren, weil sie möglicherweise mit ihrer Aufmerksamkeit abgeschweift sind.
# Als erstes werden 1000 Trials einer Versuchsperson simuliert
RTs <- rnorm(n = 1000, mean = 500, sd = 100)
# Histogram für die simulierten Daten
hist(RTs)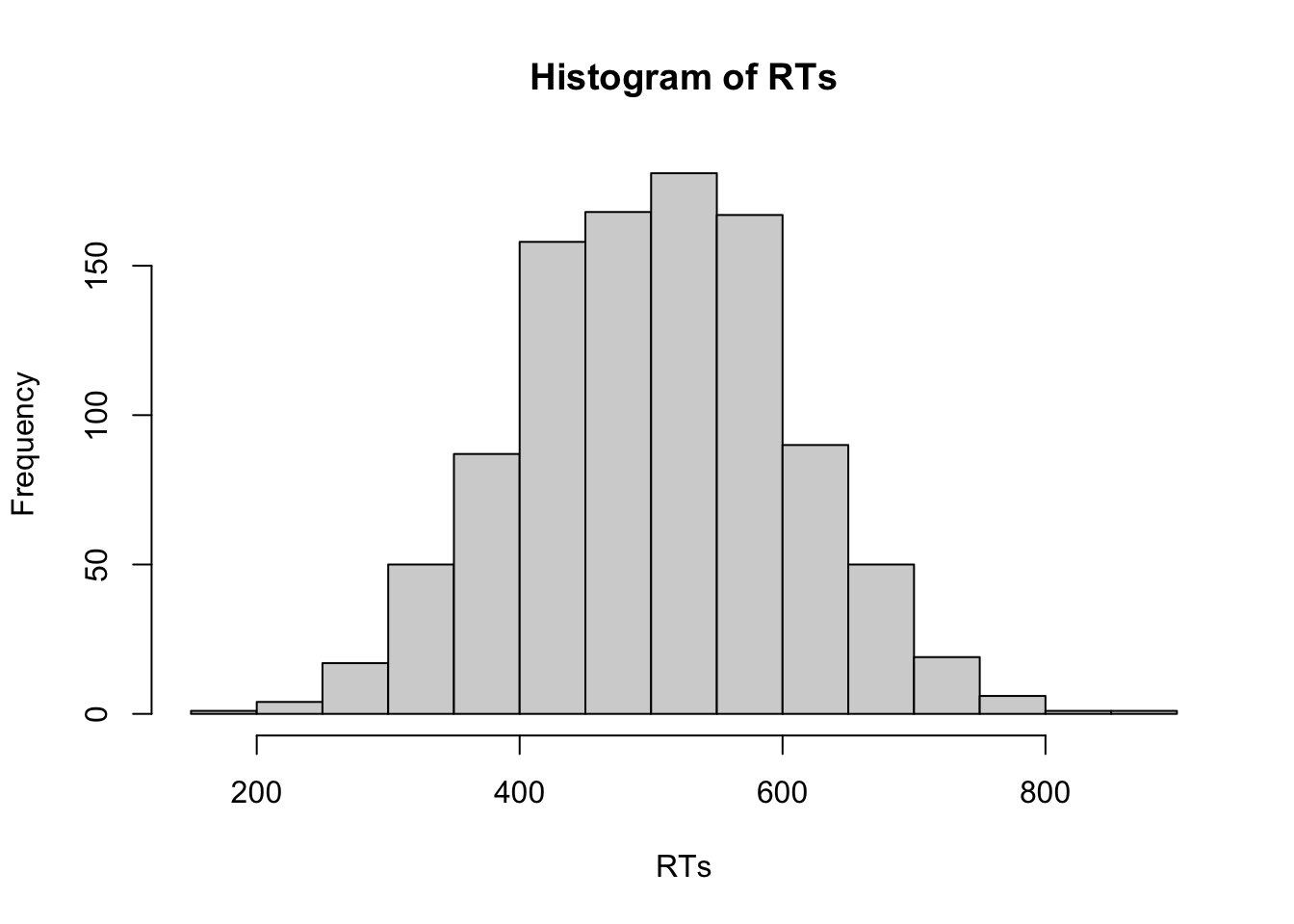
# Der folgende Vektor gibt an, welche Reaktionszeiten länger 700 ms sind
Ausreisser <- RTs > 700
# und hier werden sie durch einen `NA` ersetzt (d.h. gelöscht)
RTs[Ausreisser] <- NA
# Histogram für die Daten ohne Ausreißer
hist(RTs)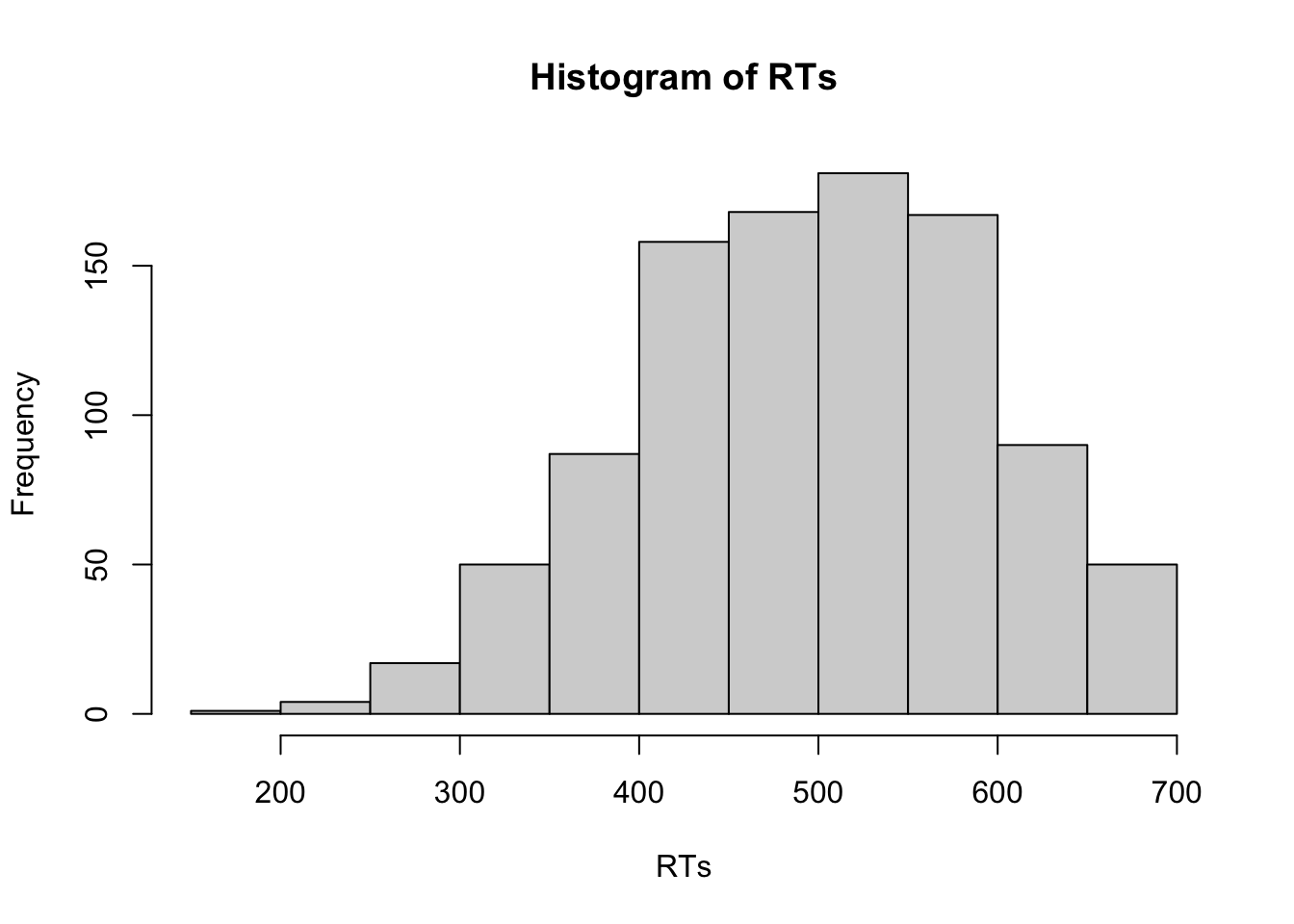
Für die ganz Eiligen: Sie können dies auch in einem einzigen Schritt durchführen, es ist dann aber fehleranfälliger. Dazu geben Sie den logischen Vergleich direkt als Index an:
RTs <- rnorm(n = 1000, mean = 500, sd = 100)
# Hier wird der logische Vergleich direkt als Index von RTs genutzt.
RTs[RTs > 700] <- NAAlternativ könnten Sie Extremwerte natürlich durch einen sinnvollen Maximalwert ersetzen. Beispielsweise lassen sich Reaktionszeiten, die länger als 700 ms sind, auf 700 ms “deckeln”.
RTs <- rnorm(n = 1000, mean = 500, sd = 100)
# Hier wird der logische Vergleich direkt als Index von RTs genutzt.
RTs[RTs > 700] <- 700Sie können auch mehrere logische Vergleiche kombinieren. In Reaktionszeitexperimenten wollen Sie meist extrem langsame sowie extrem schnelle Durchgänge ausschließen, weil Sie nicht sicher sein können, ob die Versuchspersonen vorschnell reagiert haben (extrem schnell) oder mit ihren Gedanken nicht bei der Sache waren (extrem langsam). Dazu können Sie mehrere logische Vergleiche kombinieren.
# Als erstes werden 1000 Trials einer Versuchsperson simuliert
RTs <- rnorm(n = 1000, mean = 500, sd = 100)
# Dann werden untere und obere Grenzen als Variablen definiert. Dies hat den
# Vorteil, dass Sie einfach diese Variablen im Code anpassen können, wenn Sie
# die Kriterien zur Ausreißeranalyse anpassen möchten.
untere_Grenze <- 300
obere_Grenze <- 700
# In diesem Vektor von Reaktionszeiten werden alle RTs, die schneller als 300 ms
# oder länger als 700 ms sind, entfernt. Dazu wird der logische ODER-Operator
# benötigt; es sollen solche Trials identifiziert werden, die < 300 ms ODER
# > 700 ms sind.
Ausreisser <- (RTs > obere_Grenze | RTs < untere_Grenze)
RTs[Ausreisser] <- NA
# Im Histogramm ist zu sehen, dass sowohl sehr schnelle als auch sehr langsame
# Trials aus den Daten entfernt wurden.
hist(RTs)